5. 次世代トラヒックエンジニアリングに関する研究
5.1. トラヒック変動に追随するトラヒックエンジニアリングに関する研究
5.1.1. トラヒック変動耐性を考慮した仮想ネットワーク構築手法
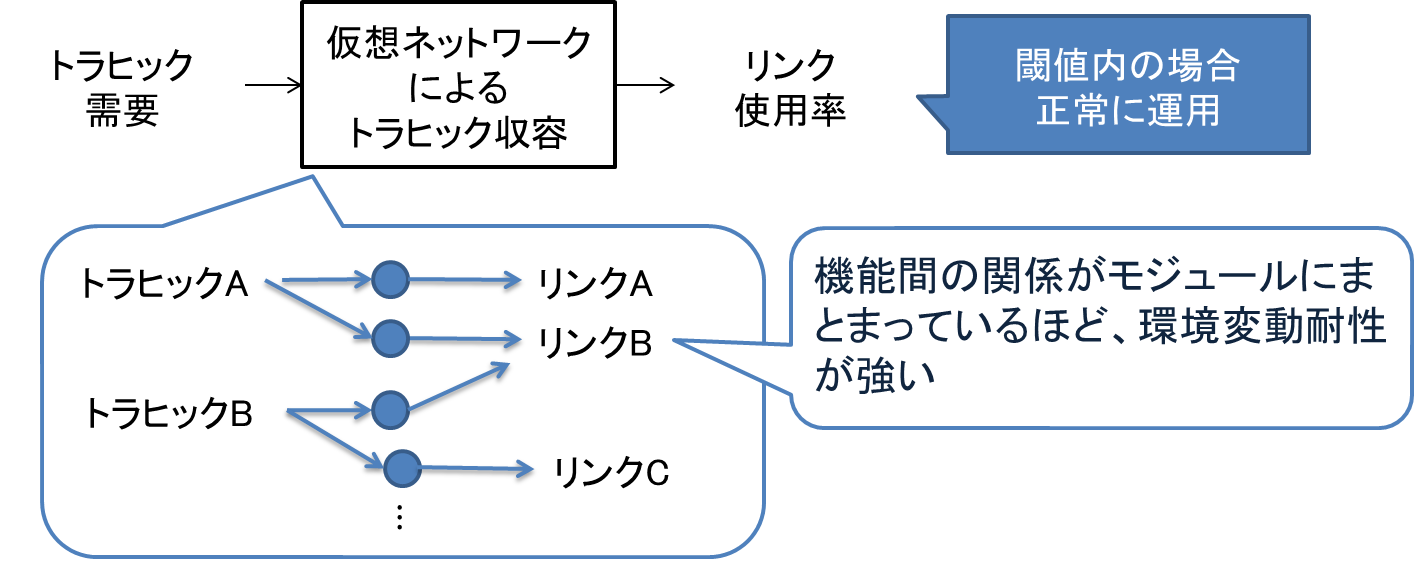
クラウドストレージサービス等の様々なネットワークサービスが普及するにつれ、ネットワークを流れるトラヒック量やその時間変動が増大している。このような大容量で時間変化の大きなトラヒックを効率的に収容する方法として、光ネットワーク上に仮想ネットワークを構築し、仮想ネットワークを動的に再構成する手法が提案されている。しかしながら、構築された仮想ネットワークによっては、発生した環境変動に対応するために、大規模な仮想ネットワークの再構成が必要となり、環境変動への対応に時間がかかってしまうという問題も発生する。そこで、本研究では、環境変動への耐性を持つ仮想ネットワークをあらかじめ構築するプロアクティブ型仮想ネットワーク制御を行うことにより、大規模な再構成を行うことなく予測困難な環境変動に対しても小規模なパスの追加のみで対応可能な手法の検討を行う。
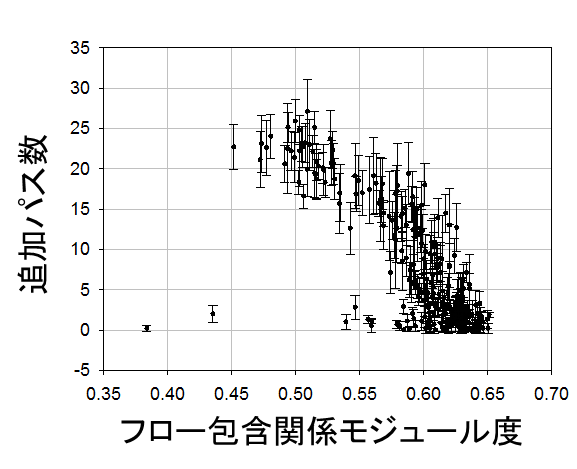
本研究では、まず、環境変動に対応して進化する生物が持つ特徴に着想を得て、環境変動に少数のパスの再構成で対応可能な仮想ネットワークが持つ特徴を明らかにする。その結果、その特性を表す指標として、フロー包含関係モジュール度(FIRM)を提案する。そして、FIRM を高く維持するための、プロアクティブ型仮想ネットワーク制御手法を提案する。本研究では、シミュレーションにより、FIRM が環境変動への対応に必要なリンクの追加数を示す指標であること、提案するプロアクティブ再構成を行うことにより、トラヒック変動発生時に追加が必要なパス数を30%削減できることが明らかになった。
[関連発表論文]
- Masahiro Yoshinari, Yuichi Ohsita, and Masayuki Murata, “Virtual network reconfigu-ration with adaptability to traffic changes,” IEEE/OSA Journal of Optical Communica-tions and Networking, vol. 6, no. 6, pp. 523-535, June 2014.
5.1.2. トラヒックエンジニアリングのためのトラヒック予測(NTTネットワーク基盤技術研究所との共同研究)
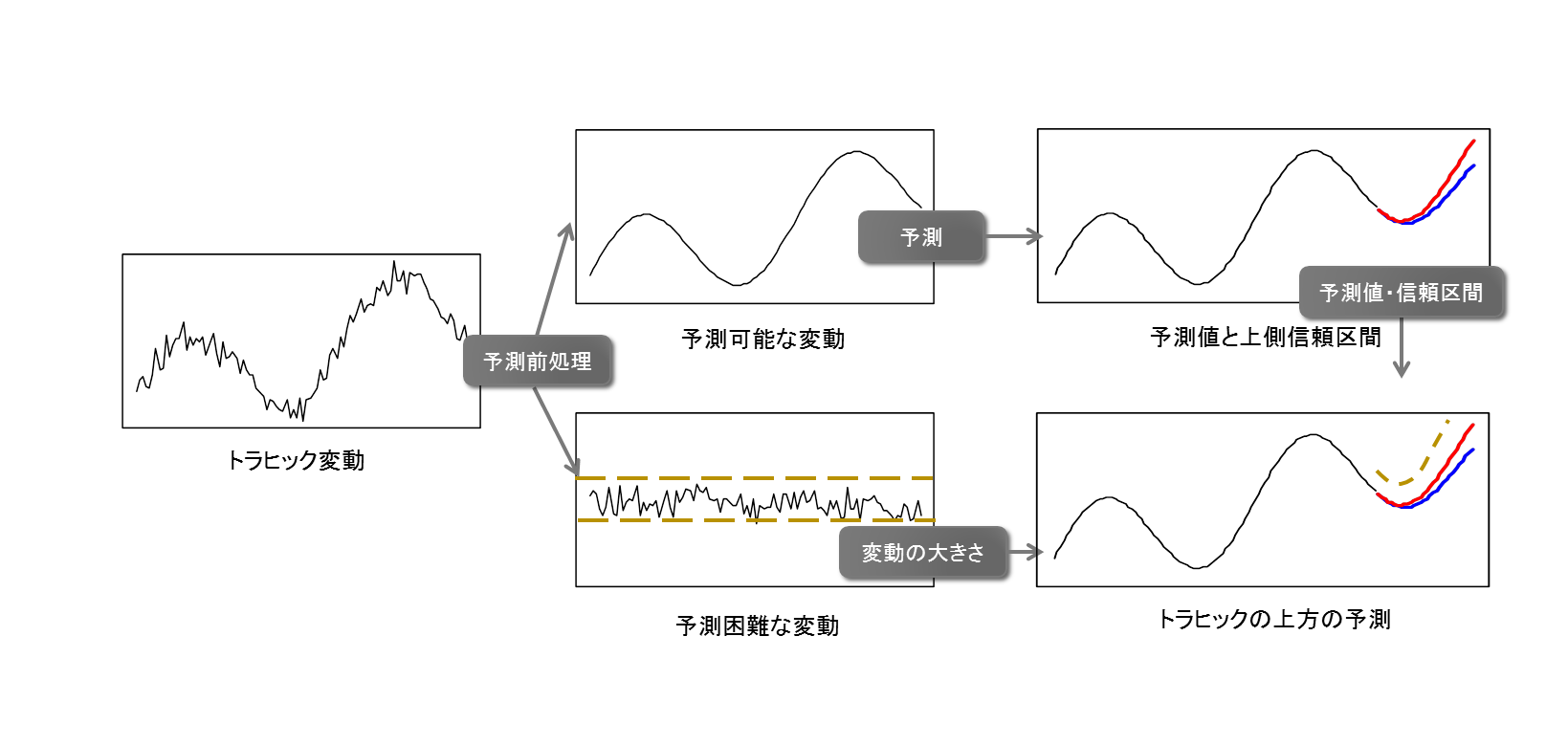
時間変動の大きなトラヒックを収容する手法として、トラヒックの時間変動やネットワークの状態の変化に対して動的に経路を変更するトラヒックエンジニアリングと呼ばれる手法の検討が進められている。しかし、各時刻のトラヒック量のみを考慮したトラヒックエンジニアリングでは、頻繁に大規模な経路変更が発生し、トラヒックを安定して収容することができない可能性がある。そのため、動的な経路変更を行う際にも、将来にわたるトラヒック変動を予測し、それを踏まえた制御が必要となる。
本研究では、トラヒックエンジニアリングに適したトラヒック予測の検討を行っている。ネットワークを流れるトラヒックは周期的で予測が容易な変動と、予測困難な変動が混在している。そこで本研究では、予測の前処理として予測が容易な変動を取り出し、予測が容易な変動に対する予測と、それ以外の変動の大きさの見積を分けて行った上で、それらをもとにトラヒック変動の信頼区間を得る。
本研究では、さまざまな前処理手法と予測モデルの組み合わせについて、Internet2 で観測されたデータを用いて評価を行い、主成分分析を用いたSARIMA モデルによる予測が過大評価を小さく保ちつつ、過小評価を1%に抑えるということを明らかにしている。
[関連発表論文]
- Tatsuya Otoshi, Yuichi Ohsita, Masayuki Murata, Yousuke Takahashi, Keisuke Ishi-bashi, and Kohei Shiomoto, “Traffic prediction for dynamic traffic engineering,” submitted for publication, September 2014.
5.1.3. モデル予測制御を用いたトラヒックエンジニアリング手法(NTTネットワーク基盤技術研究所との共同研究)
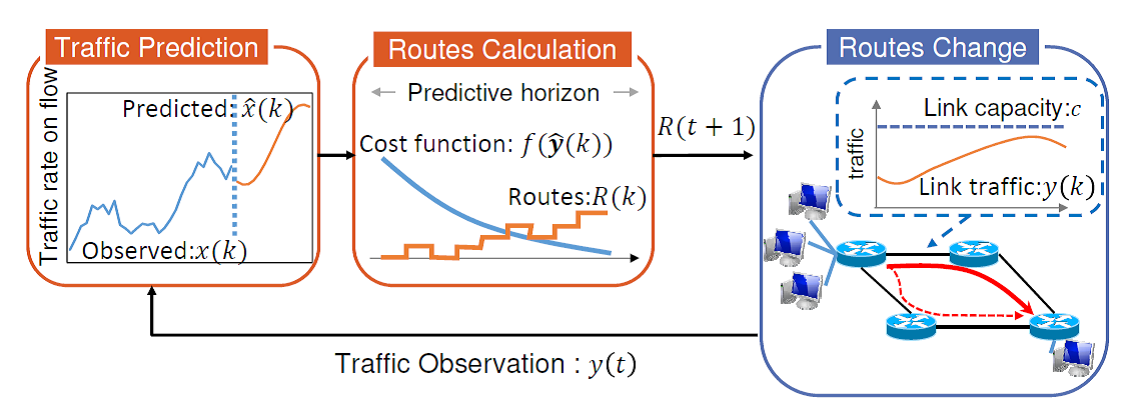
近年、ストリーミング配信やクラウドサービス等のインターネットを介したサービスが普及するにつれて、ネットワークを流れるトラヒックの時間変動は大きくなってきている。バックボーンネットワークでは、このような大きなトラヒック変動が生じる場合にも、輻輳を生じることなく全トラヒックを収容する必要がある。単純な方法としては、トラヒック需要に対してリンクの帯域を過剰に増設するオーバープロビジョニングがあるが、この場合、不必要に大きな帯域を用意するため、過剰な設備投資コストを要する。また、近年、リンク利用率の低い不要なポートの電源をオフにすることで、消費電力を削減するなど、限られたリンク帯域でトラヒックを収容することが求められてきている。ネットワークの資源を効率的に利用することで、限られた資源下においても、輻輳を生じることなくトラヒックを収容する技術として、トラヒックエンジニアリング (TE: Traffic Engineering)がある。TEでは定期的なトラヒックの観測により、トラヒック変動を把握し、各時刻で観測されたトラヒックに合致した経路を設定する。しかしながら、従来のTEでは、観測時点に合わせた経路を設定するのみであり、経路変更後に発生したトラヒック変動に対応できず、輻輳を生じる可能性がある。このような問題を解消する方法として、トラヒック予測と連携し、予測された将来のトラヒック変動を考慮したTEが考えられる。この手法では、定期的に観測されたトラヒック変動を基に将来のトラヒック変動を予測し、その予測値に合わせた経路の設定を行う。これにより、トラヒック変動に先立って経路変更を進めることができ、トラヒック変動時にも輻輳を回避した経路を設定可能である。もちろん、トラヒック予測には予測誤差が含まれるため、観測値のかわりに単純に予測値を用いるだけでは、予測誤差の影響を受けた不適切な経路変更を行う可能性がある。本研究では、予測を用いた制御理論であるモデル予測制御 (MPC: Model Predictive Control)の考え方をTEに取り入れ、予測を修正しながら、経路を再計算することで、予測誤差が生じた場合にも即座に修正の可能なTE手法を提案した。そして、実データを用いたシミュレーションにより、提案手法が、予測誤差の生じる場合においても、輻輳を回避した動的な経路設定を行うことができることを示した。
本研究では、さらに、ネットワークの規模が大きくなった際にも、短時間で将来のトラヒック予測を踏まえた経路の計算を行うため、ネットワークを階層的に複数の範囲に分割し、分割された各範囲でトラヒック予測及び、経路制御を行うことで、制御負荷を削減しつつ全体の経路制御を実行する手法も提案した。その結果、100台規模のネットワークにおいても、階層的な分割を行うことにより、10秒以内で適切な経路を計算できることを示した。
[関連発表論文]
- Tatsuya Otoshi, Yuichi Ohsita, Masayuki Murata, Yousuke Takahashi, Noriaki Ka-miyama, Keisuke Ishibashi, Kohei Shiomoto, and Tomoaki Hashimoto, “Traffic engi-neering based on model predictive control,” submitted for publication, September 2014.
- Tatsuya Otoshi, Yuichi Ohsita, Masayuki Murata, Yousuke Takahashi, Keisuke Ishi-bashi, Kohei Shiomoto, and Tomoaki Hashimoto, “Traffic engineering based on sto-chastic model predictive control for uncertain traffic change,” to be presented at The Seventh IFIP/IEEE International Workshop on Management of the Future Internet (ManFI 2015), (Ottawa), May 2015.
- 大下 裕一, 大歳 達也, 村田 正幸, 高橋 洋介, 石橋 圭介, 上山 憲昭, 塩本 公平, “モデル予測制御にもとづく仮想ネットワーク間資源調停,” 電子情報通信学会技術研究報告 (IN2014-74), vol. 114, pp. 1-6, November 2014.
- 大歳 達也, 大下 裕一, 村田 正幸, 高橋 洋介, 石橋 圭介, 塩本 公平, 橋本 智昭, “確率的モデル予測制御に基づくトラヒックエンジニアリング,” 電子情報通信学会技術研究報告 (IN2014-81), vol. 114, pp. 1-6, November 2014.
- 大歳 達也, 大下 裕一, 村田 正幸, 高橋 洋介, 石橋 圭介, 塩本 公平, 橋本 智昭, “モデル予測制御を用いた階層型トラヒックエンジニアリング,” 電子情報通信学会技術研究報告 (IN2014-136), vol. 114, pp. 91-96, March 2015.
- 河島 滉太, “分散型モデル予測制御にもとづくスケーラビリティを有する仮想ネットワーク埋め込み手法の提案と評価,” 大阪大学基礎工学部情報科学科特別研究報告, Febru-ary 2015.
5.1.4. トラヒック変動への追随を可能とする階層化トラヒックエンジニアリング手法
時間変動が大きなトラヒックを効率的に収容するには、各時刻のトラヒックに合わせて経路を動的に変更するトラヒックエンジニアリング(TE) が有効である。各時刻のトラヒックに合わせてネットワーク全体の経路を変更するためには、経路計算を行うPCE と呼ばれるサーバで、ネットワーク全体のトラヒック情報を収集する必要がある。しかしながら、大規模ネットワークでは、ネットワーク全体のトラヒック情報を頻繁に収集することや、ネットワーク全体の最適な経路を短時間で計算することは困難であり、トラヒック変動によって輻輳等の問題が生じてから、その輻輳を解消するための経路変更を行うまで時間がかかる。そこで、本研究では、ネットワークを地理的に分割、階層化を行い、頻繁に行うことが可能な局所的な制御と、長い周期で行う広い範囲の制御を組み合わせることにより、トラヒック変動発生後、すばやく、適切な経路に移行する手法を提案する。本研究では、シミュレーション評価により、階層化せずに全リンクの情報を用いたTEと比較して、提案手法は半分以下の時間で輻輳を解消することができることが明らかにしている。
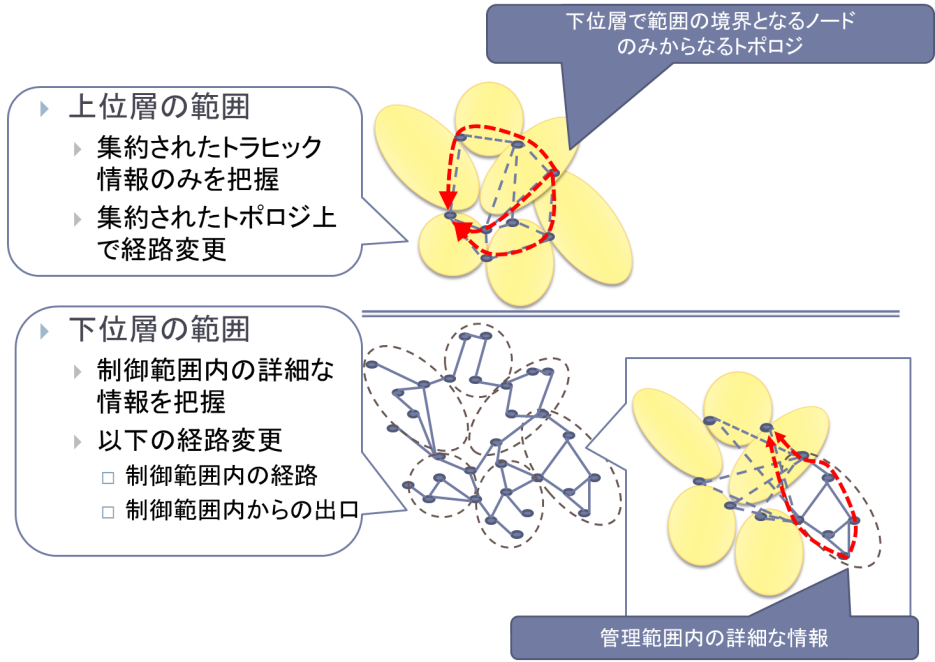
[関連発表論文]
- Yuichi Ohsita, Takashi Miyamura, Shin’ichi Arakawa, Shohei Kamamura, Daisaku Shi-mazaki, Kohei Shiomoto, Atsushi Hiramatsu, and Masayuki Murata, “Aggregation of traffic information for hierarchical routing reconfiguration,” Computer Networks, vol. 76, pp. 242-258, January 2015.
5.2 トラヒックエンジニアリングを目的としたトラヒック測定に関する研究
5.2.1. トラヒックエンジニアリングのための細粒度トラヒック観測
近年研究が進められている細粒度の経路制御手法は、経路制御を行う粒度に応じたトラヒック情報が入力として必要である。また、トラヒック予測と連携した経路制御に関する検討も進められており、トラヒック予測を行うためには、トラヒックの過去から現在にわたる時系列データが必要となる。本研究では、任意の粒度でのトラヒック時系列データを取得可能なフロー情報の観測・格納方法について議論を行う。本研究では、木構造に基づいた、フロー情報格納のためのデータ構造を提案した。その後、そのデータ構造を用いた場合に、情報更新にかかる計算時間、フロー情報の保持に必要な領域の大きさについて議論を行った。その結果、提案したデータ構造にフロー情報を整理することにより、任意の粒度のトラヒック情報をミリ秒以下の短い時間で取得することが可能となることを明らかにした。
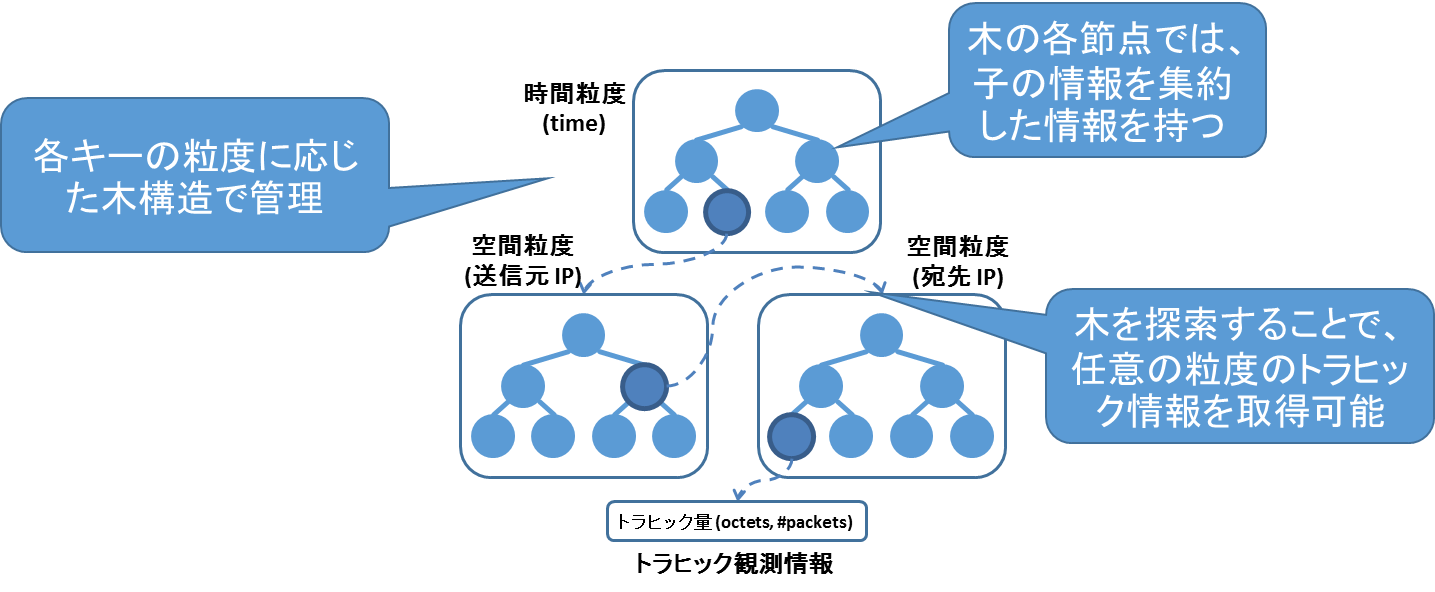
[関連発表論文]
- Yoshihiro Tsuji, Yuichi Ohsita, and Masayuki Murata, “Data structure enabling retrieval of time series of traffic with the requested granularity,” in Proceedings of IEEE Inter-national Conference on Communication Systems (ICCS 2014), pp. 549-553, November 2014.
5.2.2. トラヒック統計情報を用いたフロー分類への群知能に基づくクラスタリング手法の適用
インターネットの普及に伴い、多種多様なサービスがインターネットを介して提供されるようになり、ネットワークに対するサービスの性能要求も多岐にわたる状況となってきている。ネットワーク管理者はサービスによって異なる性能要求を満たしつつ、各サービスのトラヒックを収容する必要がある。このように多様な性能要求に合わせてトラヒックの収容を行うためには、ネットワーク内を流れるトラヒックを性能要求に合わせて分類することが必要となる。
性能要求に応じてトラヒックの分類・識別を行う手法のとして、トラヒックの統計情報をもとにした手法が注目されている。これらの手法では、各フローの統計情報を取得し、機械学習を用いて各フローの分類を行う。機械学習手法の中でも、特にクラスタリングと呼ばれる類似のデータを集めたクラスタを構成する手法は、事前に各分類先の特徴を学習することなく分類を行うことが可能であり広く用いられている。
近年、データマイニングの分野においてクラスタリング手法に関する研究も進められており、中でも生物学に知見を得た手法はクラスタリングの正確性と計算量のバランスの良さから注目を集めている。これらの新たなクラスタリング手法をトラヒック分類に適用することにより、正確な分類と短い計算時間での分類の両立が可能となると考えられる。しかしながら、これらの新たな手法をトラヒック分類へ適用した際の性能については、十分な議論が行われていない。
本研究では、 Web アプリケーションによるトラヒックの分類に焦点をあて、トラヒック分類器に群知能にもとづいた手法を含む複数のクラスタリング手法を適用し、それらの比較評価を行った。その結果、従来型のクラスタリング手法である K-means 法や群平均法は、パラメータを分類対象のデータ内に含まれているトラヒックの種類の数に合わせて設定しないと、6 割以上のフローを誤ったクラスタに分類ししまうアプリケーションが生じるなど、正確な分類ができないのに対して、群知能にもとづいたクラスタリング手法である AntTree は、単一のパラメータ設定により分類対象のデータ内に含まれているトラヒックの種類の数によらず、すべてのアプリケーションに対して 6 割以上の割合でフローを正しいクラスタに分類できることが分かった。
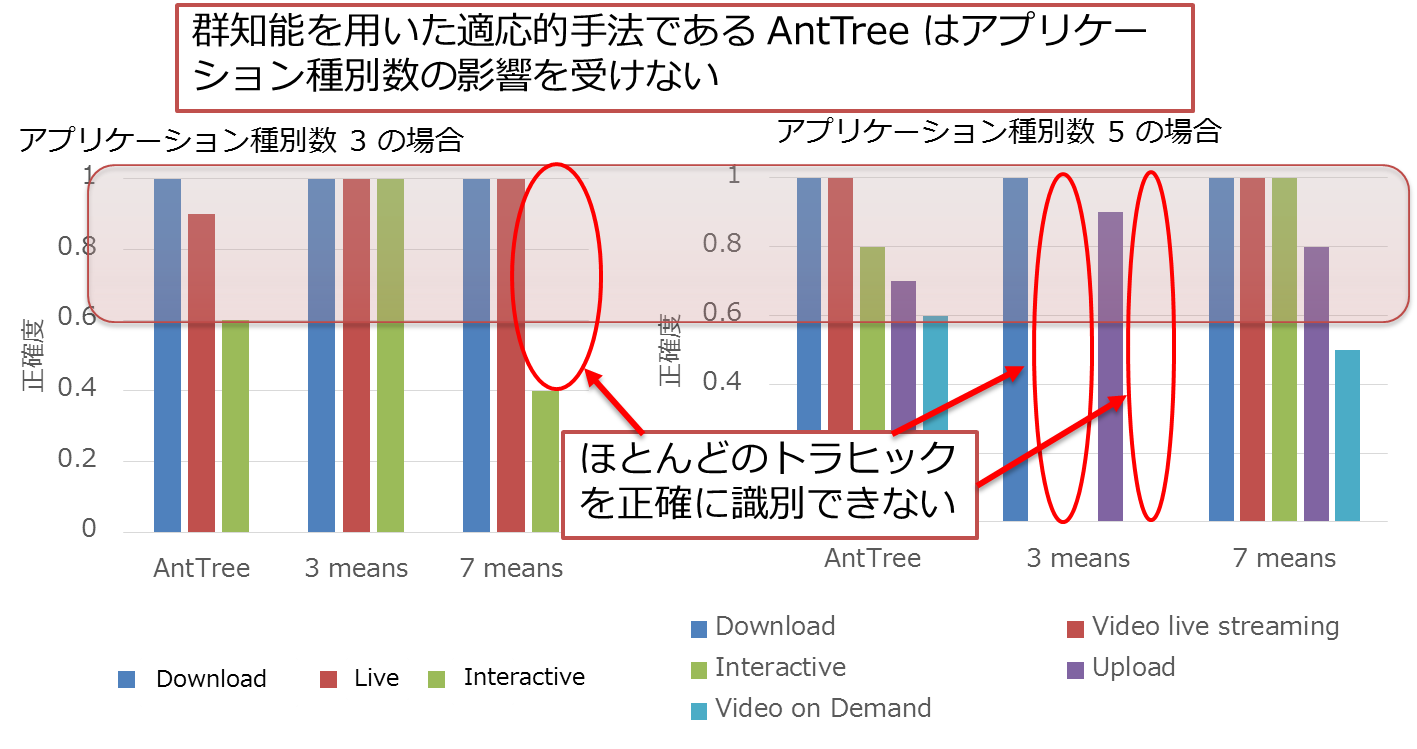
[関連発表論文]
- 須恵 匠, 大下 裕一, 村田 正幸, “群知能を用いたクラスタリング手法のトラヒック分類への適用と評価,” 電子情報通信学会技術研究報告 (IN2014-15) , pp. 37242, May 2014.
5.2.3. 圧縮センシングを利用した時空間トラヒック情報収集手法(NTT先端集積デバイス研究所との共同研究)
短い時間間隔でネットワークを制御するためには、短い時間間隔でのトラヒック観測情報の収集が必要となる。しかしながら、短い時間間隔でネットワーク内の各機器からトラヒック情報を収集すると、多数のノードからの大量のトラヒック観測情報が短い時間間隔で定期的に管理サーバに送られることになり、結果として、管理サーバ付近のリンクは特に混雑してしまう。 本研究では、ネットワークに大きな負荷を与えることなく、トラヒック観測情報を収集する方法を提案する。この方法では、トラヒック観測器がそれぞれで観測すべきフローの時系列モデルを生成し、管理サーバと共有しておく。そして、時系列モデルとの差分データのみを管理サーバを根とする経路にそって、圧縮センシングの考え方を用いた圧縮を行いながら送信する。管理サーバでは、受信したデータから差分データを復元し、時系列モデルとの和をとることにより、各フローのトラヒック情報を生成する。このアプローチによって、トラヒック観測情報転送にかかる管理サーバ付近のリンクへの圧迫を防ぐことができる。
本研究では、数量的なシミュレーションによって提案手法を評価した。その結果、提案手法によるトラヒック情報収集を行った場合、モデル誤差の大きいフロー数を観測フロー数の四分の一に抑えることができると、全フローエントリの半分のエントリ数に圧縮した情報から、相対誤差10%以下の精度でトラヒック情報を把握可能であることが分かった。
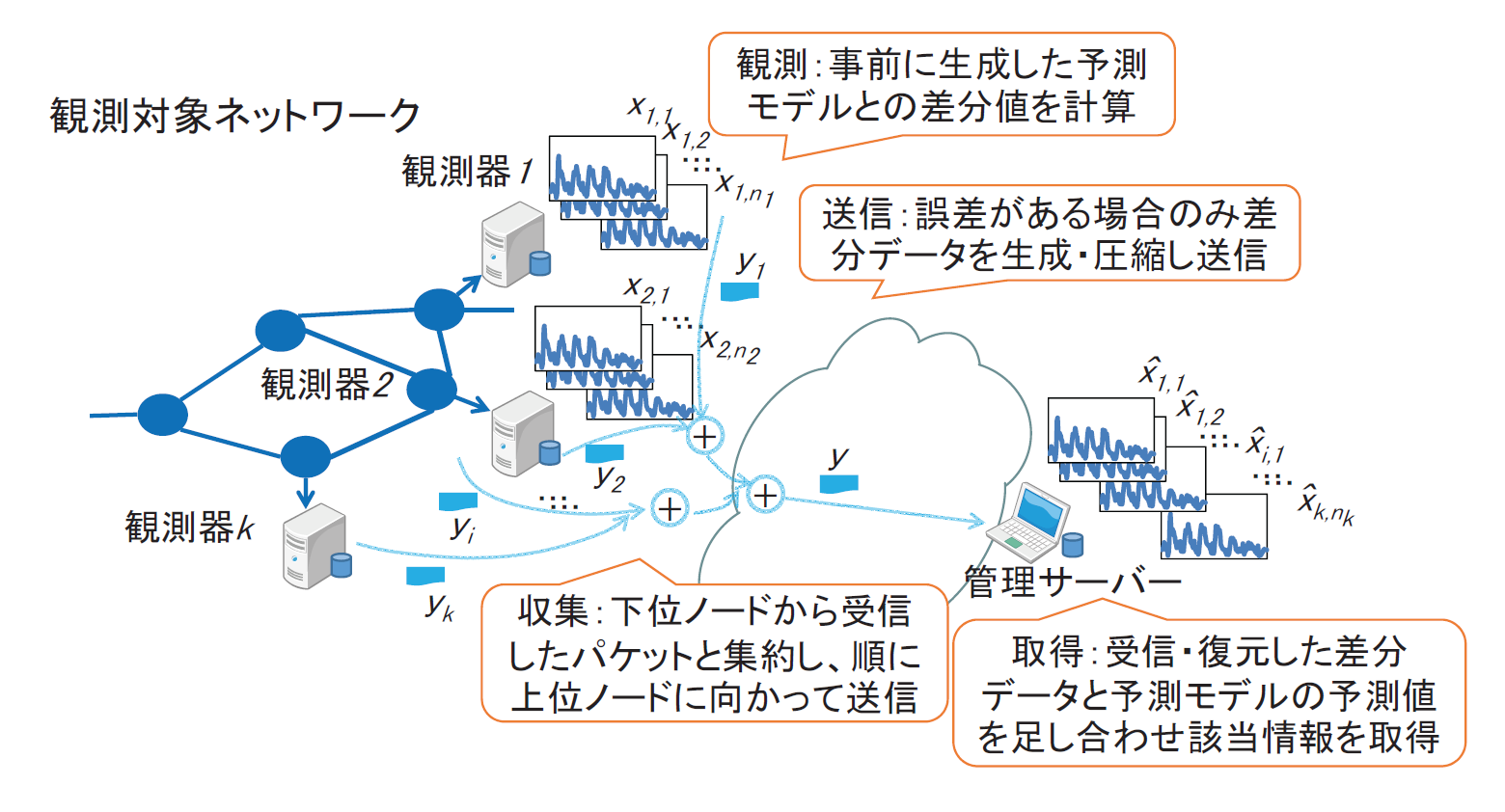
[関連発表論文]
- Yoshihiro Tsuji, “Hierarchically structured spatio-temporal traffic measurement utiliz-ing compressive sensing,” Master’s thesis, Graduate School of Information Science and Technology, Osaka University, February 2015.
- 辻 喜宏,大下 裕一,村田 正幸,山崎晃嗣,宮崎昭彦, “圧縮センシングを用いた時空間階層化トラヒック観測手法,” 電子情報通信学会技術研究報告 (IN2014-162), vol. 114, pp. 243-248, March 2015.
5.2.4. スマートフォンアプリケーションのパケット分類手法(NTTネットワーク基盤技術研究所との共同研究)
スマートフォンのアプリケーションの動作はアプリケーション開発者に委ねられているため、各アプリケーションが生成するトラヒックは、従来のフィーチャフォンの音声やキャリアが提供するi-mode 等のサービスが生成するトラヒックとは異なり、アプリケーションはサービスプロバイダのサーバとつながって様々なトラヒックを発生させ、事前に見積もるのは困難である。これら個々のトラヒックがネットワーク内で多重化された場合には、ランダムなトラヒックではなく、固有なトラヒックパターンを発生させ、場合によって急激なトラヒックの変動が発生する。また、アプリケーションとサーバとの通信が頻発すると、ネットワーク内の制御サーバとスマートフォンとの制御信号のやりとりが増大し、制御サーバに過大な負荷を与える。この様なスマートフォンアプリケーションによるネットワークへのインパクトを、アプリケーションが普及する前に算出できれば、アプリケーション普及前に対策を講じることが可能となる。
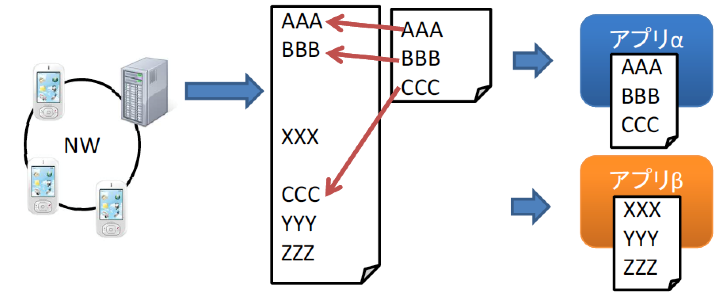
そこで本研究では、スマートフォン上の多様なアプリケーションと通信パターンについての調査を行うため、多くのスマートフォンを収容するネットワークでのキャプチャ結果をアプリケーションごとのパケットに分類する手法の検討を行った。検討した手法は、まず、スマートフォンアプリケーションのプログラムを解析し、通信するサーバのホスト名に対応する文字列を抽出する。一方、スマートフォンを収容するネットワークにおいて、スマートフォンのパケットをキャプチャし、スマートフォン毎にキャプチャデータを分類する。これには、スマートフォン毎のIP アドレスを用いる。その後、予め生成しておいたアプリケーションごとの宛先ホスト名に一致するパケットを抽出することで、アプリケーションごとのパケットに分類する。複数の実アプリケーションを用いて検証を行った結果、多くのアプリケーションについて高い適合率と再現率が得られることがわかった。
[関連発表論文]
- 中野 雄介, 上山 憲昭, 塩本 公平, 長谷川 剛, 村田 正幸, 宮原 秀夫, “混在するスマートフォンアプリケーションのパケット分類手法,” 電子情報通信学会ネットワークソフトウェア研究会, January 2015.