|
|
|

![]()
|
|
| Towards High-Speed and High-Quality InternetSupporting QoS for Real-Time MultimediaBy the Internet community, an effort to establish the connection-oriented service analogous to the conventional telephone network has recently been made. It is called ISPN (Integrated Services Packet Network) or intserv (Integrated Services Architecture) in the IETF. An analogy to the telephone network means that intserv requires
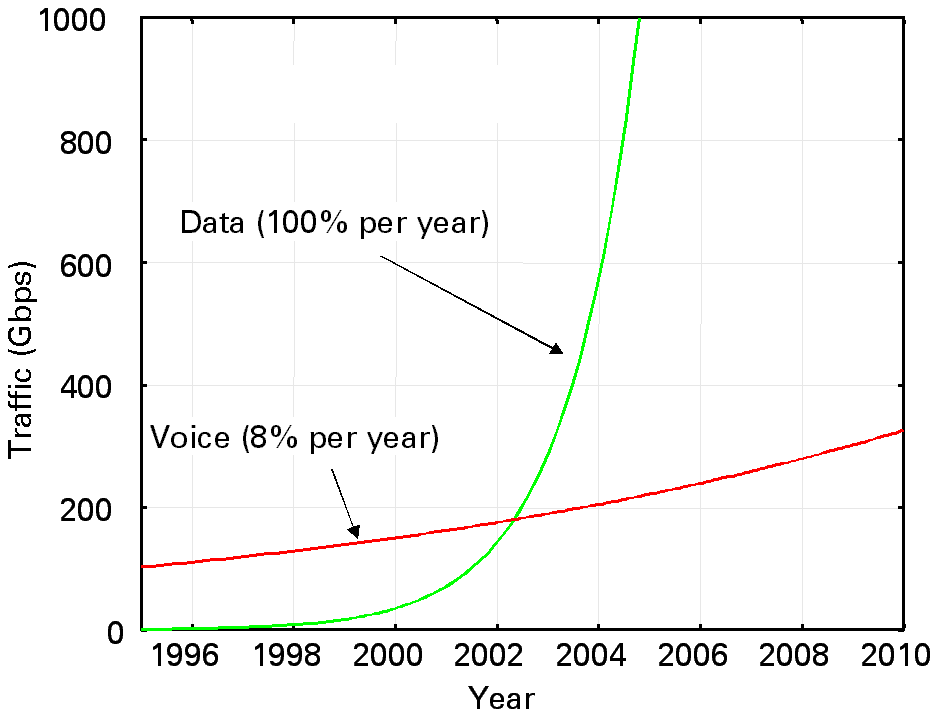
Those are implemented in a form of RSVP and WFQ (and its variants), respectively. By integrating those two mechanisms, we have a connection-oriented service on the Internet, and QoS of real-time multimedia is guaranteed. One important research area in this field is that many researches have been neglecting QoS guarantees at the end hosts. One approach is to utilize the real-time OS to integrate QoS guarantee mechanisms at end systems and networks. As intserv is deployed, however, its problem has also been pointed out. It is scalability. The first scalability problem exists in the signaling protocol, which should be passed by all the routers along the path between end systems. The second is related to the packet scheduling algorithm of WFQ. As the number of active connections on the router increases, processing time at the router is increased. It follows that differentiated service (or diffserv in short) is now drawn considerable attention. The diffserv architecture is not a mechanism to guarantee QoS, but to discriminate the service grade among classes. Thus, the diffserv architecture is not a final goal for QoS guarantees of real-time multimedia. By diffserv, it can be expected that the user who pays more money can receive better performance. Another possible application of diffserv is to build VPN (Virtual Private Network) by its ability to allocate some portion of the bandwidth to the class. The question is whether we need an ISPN-like service in the current and future Internet or not? It probably depends on how much real-time multimedia applications will be deployed. If it becomes major in the future Internet, it is valuable to invest in the ISPN architecture. Another scenario we can consider is that at the edge router, we employ the WFQ-like packet scheduling algorithm to ensure better QoS of real-time applications. The core router within the network does not discriminate flows under the assumption that the backbone network becomes sufficiently fast by, e.g., the photonic technology. Building High-Speed Packet-Switching Backbone NetworksWe are now facing a data explosion in the Internet. One projection states that in the very near future, the data traffic dominates the network. Since its projection is based on the statistics of mid 90's when the Internet was rapidly accepted, the projection is likely to overestimate the future growth of data traffic. However, the tendency would continue at least for the time being.
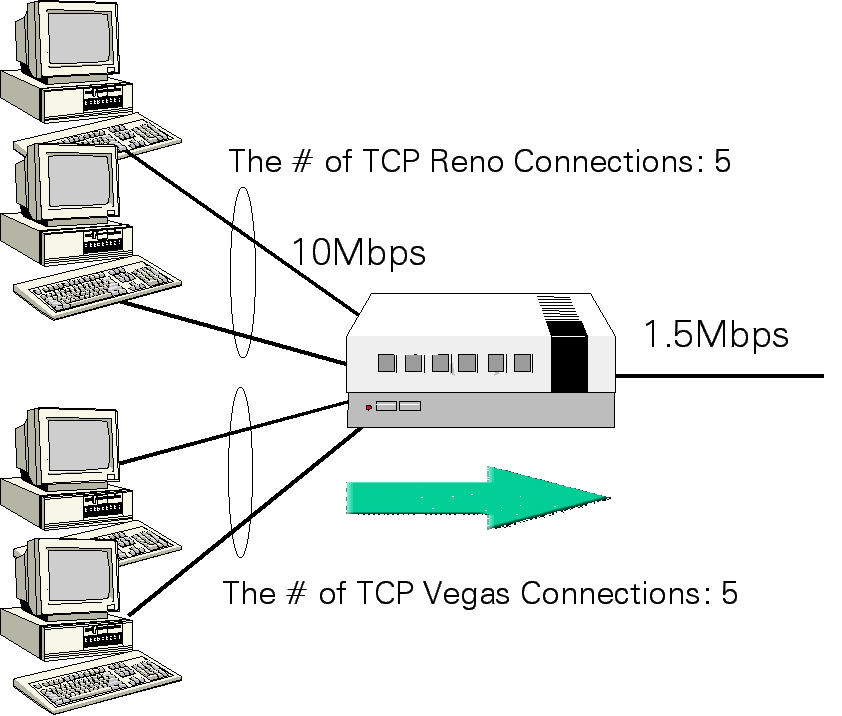
It used to be pointed out that the future killer application is multimedia applications. However, it is now proven to be incorrect. The true story is that the killer is a mass growth of the Internet users. It means that the support of the connection-oriented service (necessary for the real-time multimedia requiring large bandwidth) is not mandatory, but high-speed packet switching for the short-lived connections is important. Especially on the backbone network, the control mechanism such as the active queue management requiring per-flow queueing would not be necessary, and instead a capability of fast packet forwarding is expected. In that sense, WDM (but ATM) is promising for future data transport network. We will be back on this subject in the next section. Establishing High Performance Transport ProtocolsProblems of TCP have been repeatedly pointed out and in the early 90's, new light-weight transport protocols have been actively discussed. Those include NETBLT and XTP. However, time changes and TCP is now widely deployed in the operating network. Thus, it now becomes difficult for some new protocol (including the modified version of TCP) to take the place of TCP unless the protocol designer considers a migration path from the original TCP. Otherwise, the new protocol would not be received. One interesting example can be found in the TCP Vegas version. It is shown that TCP Vegas can achieve between 40% and 70% better throughput, with one-fifth to one-half the packet losses, as compared to the existing TCP Reno version. However, the simulation model assumes that the link is shared only by TCP Vegas connections. When those share the link with TCP Reno connections, however, TCP Reno connections easily dominate the link and receive much more throughput than TCP Vegas connections. The reason is that TCP Vegas tries to share the link modestly with other connections, while TCP Reno increases the window size until the packet is lost. That is, an aggressive increase of the window size of TCP Reno results in that TCP Reno connections first grab the link, and TCP Vegas connections miss the chance to increase its window size.
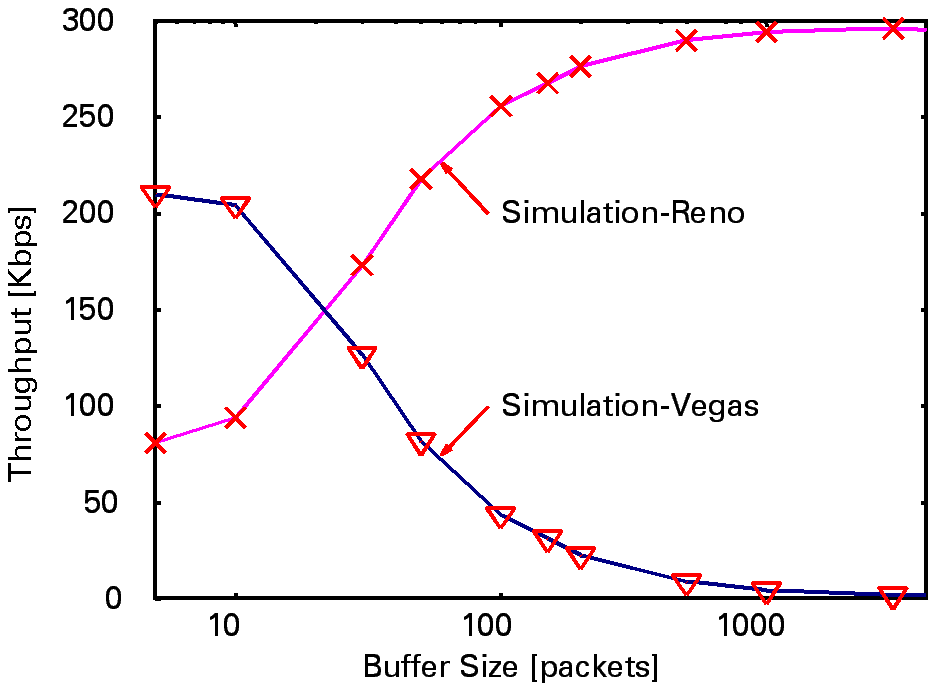
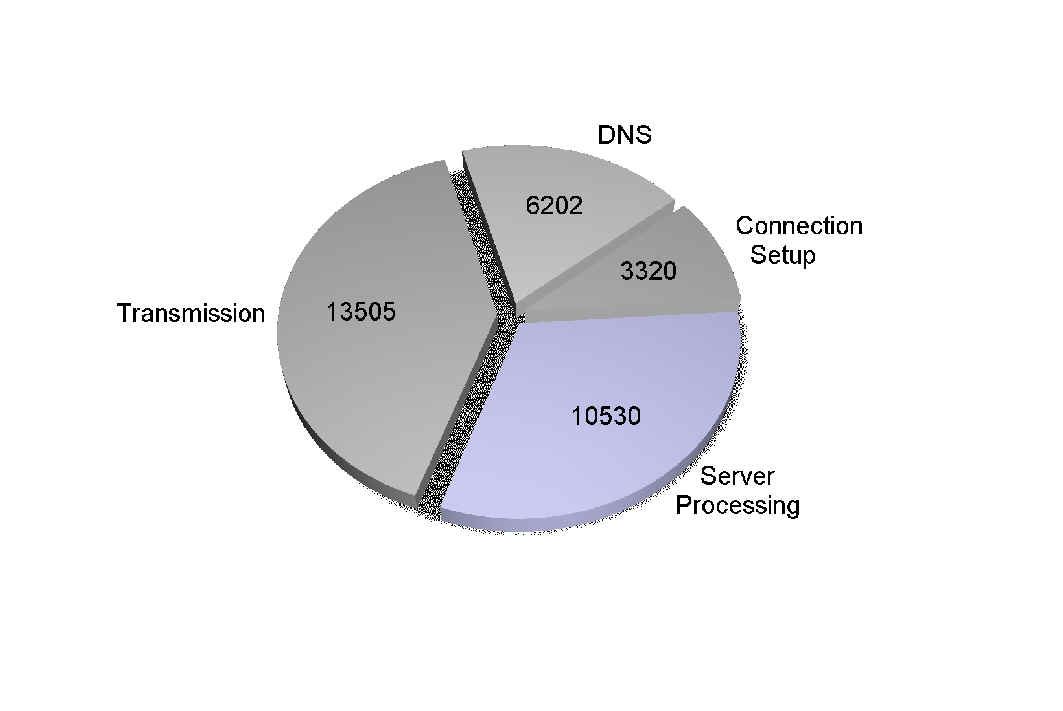
The left figure shows the network model where TCP Vegas and Reno shares the link. The right figure shows the result. Especially when the router buffer size becomes large, TCP Reno can attain much more throughput than TCP Vegas. Fortunately, the role of the receiver in the TCP mechanism is just to return ACKs (acknowledgements) as the packet is successfully received. It indicates that we have a chance to incorporate some modification at the sender side of TCP to improve the performance. In some researches, the socket buffer allocated to the TCP connections is adjusted based on the bandwidth-delay product of connections. As the number of Internet users grows, the congestion control aspect of TCP has been paid much attention. Namely, the problem is, say, how 1.5Mbps link can be shared by a thousand of users with 64Kbps access channel.. Establishing High Performance End SystemsIn the previous subsection, we argued that it is important to effectively share the link bandwidth by the number of connections. Another important aspect is how to accomplish the high-speed data transfer between end systems. As we discussed earlier, the delay is incurred at the end systems in addition to the network. It is partly demonstrated in the figure below while the delay component at the client side is not included. As the figure clearly shows, no component dominates the end-to-end delay.
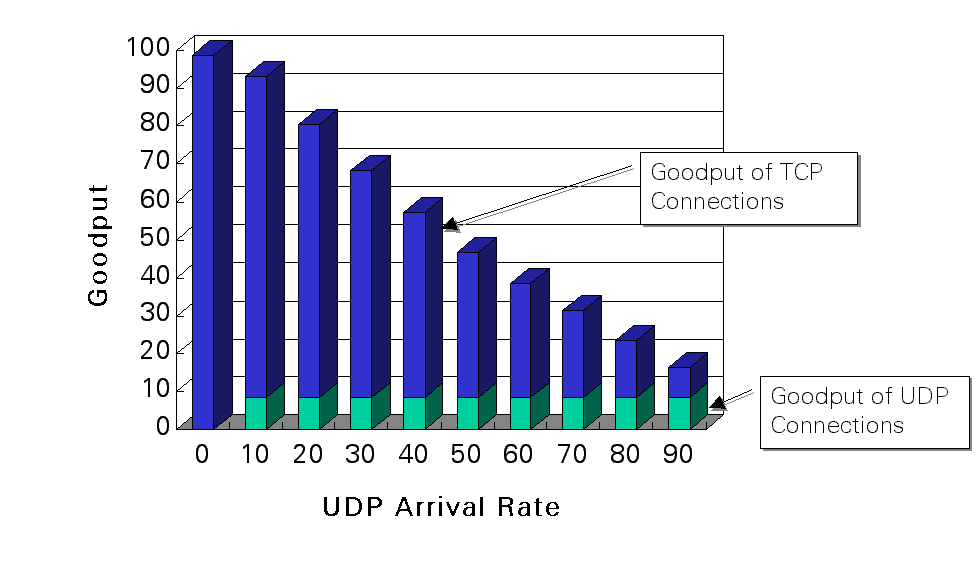
Delay components of the Web document download. The values in the figure show the 95 percentile delay in milliseconds from randomly chosen 100 sites. The figure is produced by using the data available at \url{ftp://ftp.telcordia.com/pub/huitema/stats/ Several commercial products such as Gigabit Ethernet and MAPOS have already provided the interface exceeding 1Gbps to the end system. Especially in such an environment, the role of end systems becomes important in the Internet architecture, because protocol processing of upper layers (transport and application layers) is performed at the end system. In the projection paper in early 90's, the gigabit processing would be possible even by the conventional Internet protocol hierarchy. Actually, the gigabit order of throughput is reaching by the widely used personal computer, if an overhead due to memory copy can be effectively avoided based on a zero copy technique. However, the method in Myrinet adopts a proprietary transport protocol, and more researches should be performed in this area. Keeping Fairness among ConnectionsIn the Internet, the congestion control mechanism is performed at end systems. It gives a flexibility in the Internet, but it also introduces several problems. One such a problem is fairness. A typical example is that the connections cannot receive the same throughput as described below. Such a problem would never occur if the network explicitly allocates the bandwidth to each connection, but the network is not allowed to actively perform congestion control in the Internet. The fairness problem is one of most important problems in the Internet, and we believe that it is often more important than performance issues. Fairness between TCP and UDP ConnectionsIt is now well known that when TCP and UDP connections share the link, UDP connections tend to occupy the link. It is because the UDP connection does not adequately react against the congestion while the TCP connection does. The figure below shows goodput values of UDP and TCP connections, where the simulation setting is as follows. Three TCP and one UDP connections compete over a congested 1.5Mbps link. The access links for all senders are 10Mbps, except that the access link to the receiver of the UDP flow is 128Kbps. When the UDP source rate exceeds 128Kbps, most of the UDP packets will be dropped at the output port of the link. The vertical axis shows the goodput defined as the rate successfully delivered to the receiver. All values given in the figure are defined as a fraction of the bandwidth of the 10Mbps link.
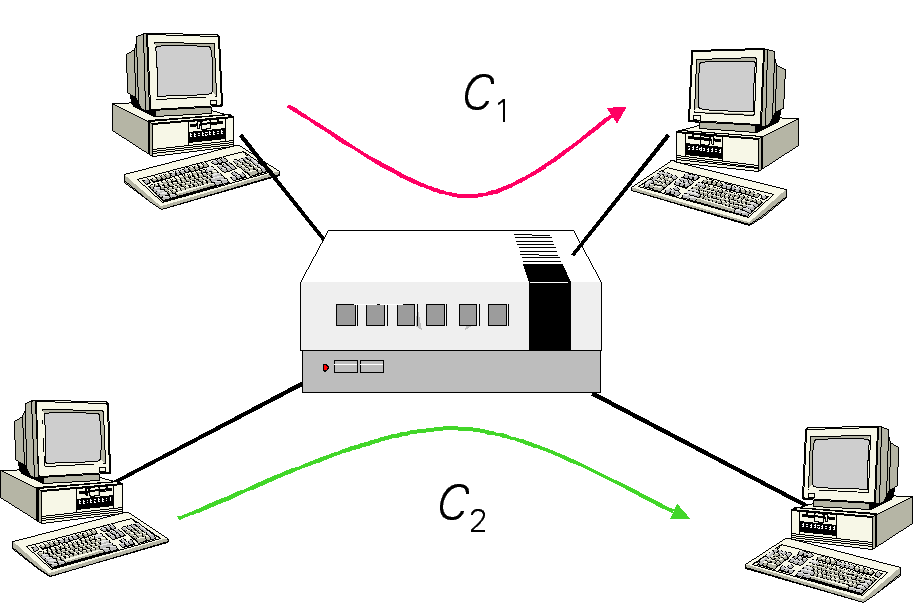
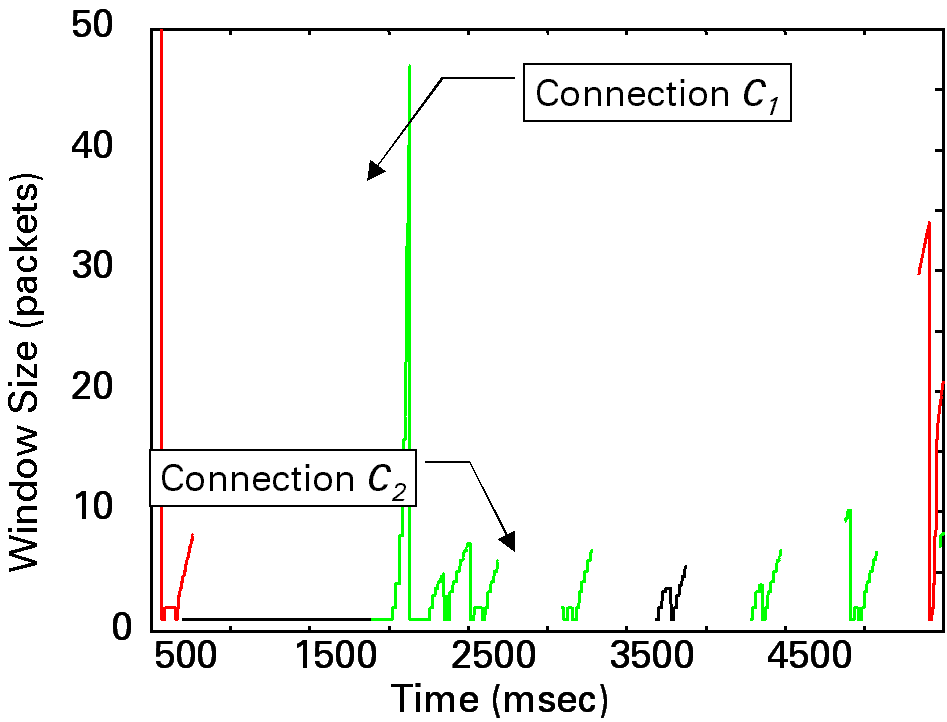
UDP connections wastes the link and TCP connections receive unfair treatment. We should note here that it is true that most of the currently available real-time multimedia applications are equipped with its proprietary delay- and/or rate-adaptive control mechanisms. However, it is only for its own purpose of performing better-quality presentation. Accordingly, a notion of {\it TCP friendly} congestion control is now proposed, where TCP friendly is defined as a non-TCP connection should receive the same share of bandwidth as a TCP connection if they traverse the same path. However, its definition still contains ambiguity; an appropriate time scale of the fair share is still not clear, which is important especially when {\it TCP-friendly} is applied to real-time multimedia. Fairness among TCP flowsDue to an intrinsic nature of the window-based congestion control mechanism of TCP, TCP connections do not receive the same instantaneous throughput even if connections share the same end-to-end path. If TCP connections have different propagation delays, even the long-term throughput values become different. An experimental example by simulation is shown in the figure below, where Connection C1 with smaller propagation delay clearly obtains the larger throughput than C2 with longer one.
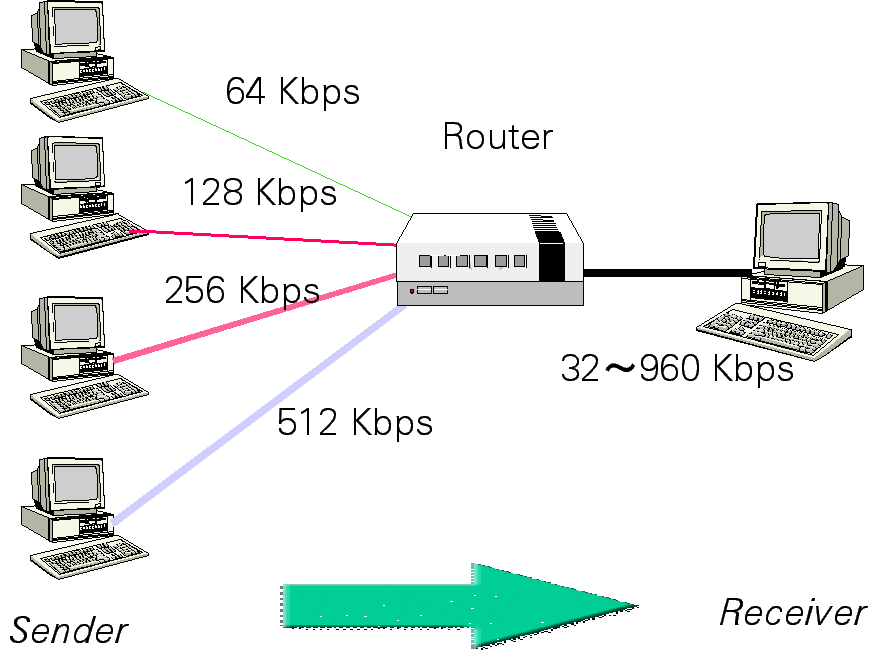
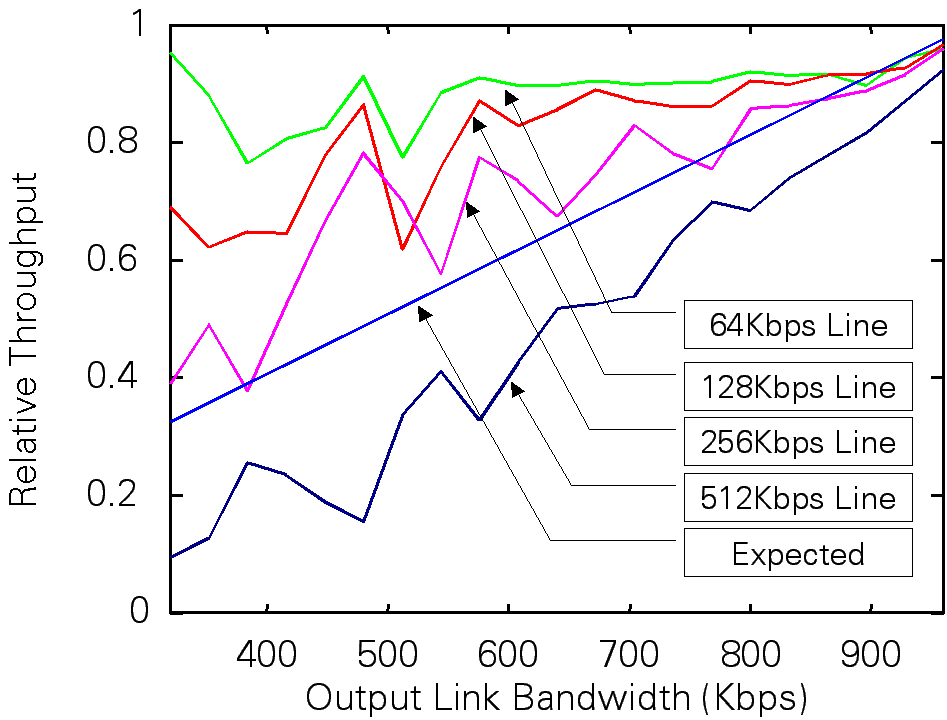
Comparisons of instantaneous throughput values of TCP connections with different propagation delays. The propagation delay of connection $C_2$ has two time larger than that of connection $C_1$. More importantly, if the bandwidth values of TCP connections are different, the relative throughput of TCP connections against its access link bandwidth are much different. It means that more bandwidth does not help improve the throughput. See the figure below for an example result. The vertical axis of the figure shows the relative throughput of the connection, which is defined as the ratio of the throughput against the capacity of the input link of the connection. The expected line shows the ideal values by our definition. Resolving this problem is important since the heterogeneous environment is becoming common as various access methods of the Internet, such as the ADSL and CATV, are realized.
Comparisons of long-term throughput values of TCP connections with different values of access link capacities. A main cause of the unfairness in TCP is owing to its AIMD (additive increase/multiplicative decrease) window updating algorithm. It has already been pointed out that only AIMD establishes the fairness among connections. However, the window updating algorithm of TCP is self-clocked. That is, the window size is only updated as the sender receives ACK from the receiver, and therefore the window curves of TCP connections with different propagation delays and/or different access link capacities become different. Then, the window updating algorithm is now actively studied. Solution techniques against the unfairness problem mentioned above and possible limitations are also discussed in the literature, which will be introduced in the next subsection. Reallocating Network FunctionsSo far, we have emphasized that the fundamental philosophy of the Internet is that the network is loosely-coupled and the control is performed in a distributed fashion. Then network functions such as congestion control is left to the end systems (i.e., TCP), and the only role of the network is to carry the bits. Of course, it is a rather philosophical statement and several control functions are tried to be moved into the network layer. Actually, fully distributed control makes it difficult to realize the fair service. It is reported that several end systems seem to modify the source code of TCP such that even if the congestion takes place within the network, the window size is not throttled. Since other TCP connections decrease the window size according to the congestion control principle, congestion is terminated and the modified TCP can enjoy better performance than others. The network should take an active queue management for achieving the fair service among TCP connections and eliminating ill-behaved connections. The first example is the RED router, which avoids the burst dropping of packets from the same connection. It results in a fair treatment of connections to some extent. DRR is another active queue management method to process packets with per-flow queueing, by which active connections at the router is fairly treated. However, the scalability problem exists in the per-flow queueing. It seems difficult for the core router to maintain the per-flow queueing and scheduling against thousands of active flows. On the other hand, the edge router could handle per-flow queueing since the number of active flows is not very large. Another extreme is an FIFO router where the packets are simply forwarded in an FIFO manner. As noted earlier, the primary objective of core routers must be fast packet forwarding and switching, and therefore the FIFO scheduling seems to be sufficient. A compromise between per-flow and FIFO queueing may also be possible while discrimination of flows becomes imperfect.. An ECN mechanism is another example that the network plays an active role against congestion. In ECN, the router actively returns the congestion information to the sender so that the congestion relief can be performed quickly. We should last recall that too complicated and restrictive control by the network looses the merit of the Internet and we need more investigation on this aspect. Establishing Network Dimensioning MethodsIt is important to provide stable performance to the user. For this purpose, adequate network dimensioning is necessary. The Erlang loss formula has been providing a powerful tool for the telephone network, where the following positive feedback loop is established.
The advantage of the above procedure is owing to the fact that the Erlang loss formula is robust in the sense that the distribution of call holding times does not matter. Only a finite average is necessary. On the other hand, dimensioning of the data network is not easy. We have several obstacles.
Perhaps, we will not be able to have a theory-based network dimensioning method like the one in the telephone network. The traffic measurement then becomes important to establish the positive feedback loop. In doing so, the following problems should be resolved.
Many of current research efforts on traffic measurement are devoted just to acquire the traffic characteristics on the link. More researches are necessary to resolve the above problems. One point that we should note here is that for effective and meaningful positive feedback loop, the flexible bandwidth management is expected. ATM has such an capability, which is well known as dynamic VP bandwidth management. Establishing A Fundamental Theory for the Network ResearchesThe fundamental theory in the data network has been a queueing theory during a long time. Its origin can be found in Kleinrock's Queueing Systems, and its usefulness is needless to say in the field. However, the queueing theory only reveals the basic property of a single entity, corresponding to the packet buffer of the router in the case of the Internet. We can find the packet queueing delay and loss probability (for the finite buffer) by applying the queueing theory. However, as described before, the QoS metric of the data network is neither packet delay time nor loss probability at the router. The performance at the router is an only component of the entire delay. It is a quite different point from the teletraffic theory (i.e., the Erlang loss formula). The derived call blocking probability is directly related to the user's perceived performance. We have another theory, called a queueing network theory, which treats the network of queues. However, it does not reflect the dynamic behavior of TCP, which is essentially the window-based dynamic congestion control. We thus need another fundamental theory to model and evaluate the data network. One promising approach is a control theory that has an ability to explicitly model the feedback loop of the congestion control.. Another important research area is on what kind of performance model should be used in evaluating network performance. When a new version of TCP is proposed, how can its effectiveness be convinced? We do not have an appropriate modeling approach for the world-wide and scalable Internet. The modeling approach needs to be further researched. We last note that in recent years, a self-similar nature of the network traffic has been paid much attention, and a fractal queueing theory becomes one of active research areas. However, the author's feeling is that it is still not clear whether we actually need a fractal queueing theory or not. It is true that the Internet traffic appear to be self-similar or at least to be heavy-tailed according to the past researches. However, most of traffic characterizations are just results on traffic measurements. While the self-similarity was observed on the Ethernet, it includes effects of the data link layer protocol (i.e., CSMA/CD of the Ethernet) and the transport layer protocol (i.e., TCP). That is, it does not directly mean that the packet arrival at, e.g., the router shows self-similarity. Other examples can be found in the case of the file transfer time on the Internet and Web documents. Just an indication drawn from those results is that the distribution of file sizes follows the heavy-tailed distribution, and is not directly related to the modeling of the self-similarity of the packet arrival. Another attention is necessary; most of past results has shown that the heavy-tailed distribution is only exhibited if we look at the tail distribution. An entire distribution often has a finite mean of log-normal distribution. See the following paper for further discussions and the sources of the above statements.
|
|
If you have any questions, please drop a note to
murata@cmc.osaka-u.ac.jp (Masayuki Murata).
|